
技术调研-网站更新一
背景
对于前端部署如何进行项目部署这里就不详细介绍了,这里主要介绍如何进行前端部署通知用户更新网站。
之前开发的网站, 每次都是让用户手动进行刷新网页打到网站更新的目的,但是这里有一个弊端,就是用户每次都需要手动,对我来讲,我比较懒,能自动的绝不手动刷新;
简单介绍
场景 1
开发完一个功能, 提交到 github 上, 然后通过jenkins去部署发布, 之后你会发现页面还是之前的页面,因为你没有刷新网站,所以需要手动刷新一下网站。对于用户来讲能不能自动更新呢?
场景 2
用户在填写表单的时候,你项目网站更新了,需要一个提示,可以立即更新也可以忽略稍后更新, 这样就可以告知用户网站更新了那些功能? 更新的内容会不会影响你正在操作的功能?
场景 3
如果没有提示框,直接刷新页面导致用户正在操作的数据丢失, 这样的损失还是比较大的;
于是我今天研究了一下这个网站更新的方案, 然后通过本地nginx模拟服务器去尝试了一下;
实现的方案
文章使用的是vite5 + vue3 + ts的一个本地项目;
- 使用第三方插件vite-plugin-pwa, 具体的做法可以参考官网
- 手动是实现
manifest.json+ 循环web worker实现, 就是打包的时候创建一个manifest.json然后将打包时间Date.now()写入文件, 之后在根据里面的时间去做对应的逻辑 - 在
vite.config.ts中使用build, 开启manifest,这样每次打包都会在dist/.vite中生成一个新的文件, 这个文件就是manifest.json
这里我们具体讲vite.config.js + web worker实现思路:
配置 vite.config.ts
vite.config.ts如何配置呢? vite 后端集成
1 | export default defineConfig(() => { |
然后你可以通过npm run build命令打包项目,等待项目打包成功之后, 项目根目录生成dist目录, 大概的结构为:
1 | .vite |
.vite目录就是我们打包的manifest.json文件, 这个文件就是我们后面需要读取的; manifest.json中file就是index.html中引入js,css的地址;index.html中引入js,css的地址为:
1 | <!-- 大概这样的格式 --> |
这里manifest.json文件可以理解为离线缓存文件, 就是吧所有的资源都缓存起来;
实现思路一
想要做到网站更新, 这里要获取manifest.json文件,不过现在文件是在dist/.vite中, 想要直接读取那就要修改打包命令
1 | "scripts": { |
copyManifest.js的文件为就是复制一份manifest.json到dist目录下
1 | import { copyFileSync } from "fs"; |
然后在main.js中引入一个文件,这个文件就是你更新网站的核心逻辑了;
大致的思路就是:
fetch('/manifest.json')拿到最新的数据和上一次的数据去做比较或者结合发布订阅模式- 循环获取, 因为网站不定时会更新,所以需要循环; 发现文件地址不一致直接弹框提示;
manifest.json你也可以手动创建, 那就需要吧vite.config.ts中manifest关闭, 打包的时候创建一个文件manifest.json内容为{time: 'xxxx', content: '更新内容'}; 同样的循环操作去对比时间;
不过这样是比较麻烦的, 所以我们使用另外一种web worker来实现;
实现思路二
首先需要创建俩个文件checkUpdate.ts和checkUpdate.worker.ts, 一个是入口文件, 另一个是web worker循环检测机制;
1 | // checkUpdate.ts: |
1 | // checkUpdate.worker.ts: |
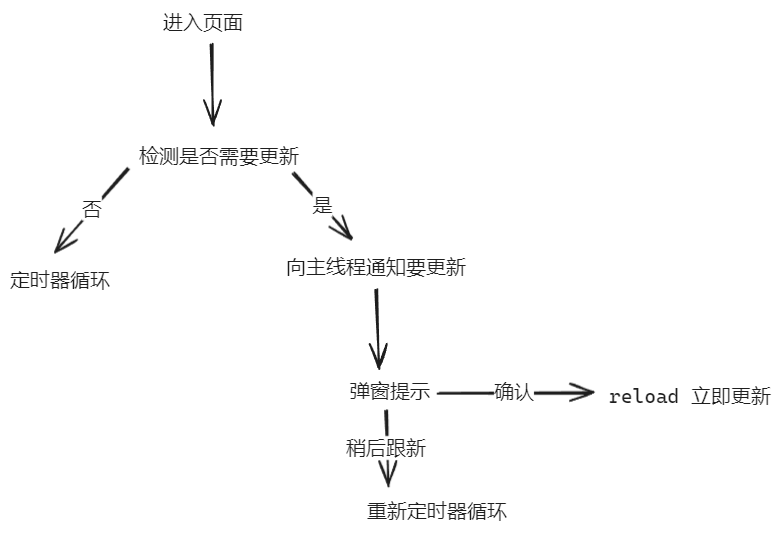
然后在main.ts中引入import './checkUpdate'; 基本上就可以了;
然后重新打包, 讲打包出来的文件放在本地服务器上;
然后打开页面: 等待时间就会有提示了:
知识补充
::: tip
使用 Web Worker 来实现网站更新,尤其是处理与页面渲染无关但可能耗时的操作,如数据解析、复杂计算、大文件处理等,可以带来以下好处:
:::
好处
- 防止主线程阻塞:
- Web Worker 在单独的后台线程中运行,与 UI 渲染线程互不干扰。这意味着即使在处理复杂的更新逻辑时,用户仍能流畅地与页面交互,避免了因长时间计算导致的页面冻结或卡顿现象,显著提升了用户体验。
- 提升响应速度:
- 对于涉及大量数据处理或计算密集型的更新任务,Web Worker 能够并行处理这些工作,使得更新过程更快完成,使得用户能更早看到更新后的结果。
- 分离任务,优化代码结构:
- 使用 Web Worker 可以将复杂的更新逻辑封装到独立的脚本中,与主线程的 UI 逻辑清晰分离。这有助于代码组织,提高可维护性,并允许开发者专注于各自线程的任务,遵循“关注点分离”原则
- 异步处理:
- Web Worker 通过消息传递机制
(postMessage() 和 onmessage)与主线程通信,实现了真正的异步操作。这使得更新任务可以在不影响主线程的情况下异步进行,符合现代 Web 应用的非阻塞、事件驱动编程模式。
- Web Worker 通过消息传递机制
- 资源加载与预处理:
- 如果网站更新涉及到资源的加载或预处理(如压缩、解密等),Web Worker 可以在后台线程提前完成这些工作,待准备好后再通知主线程,避免了资源加载对主线程的直接压力。
弊端
兼容性问题:
- 虽然 Web Worker 是 HTML5 标准的一部分,但在较老的浏览器或某些非标准环境中可能存在兼容性问题。开发者需要进行兼容性检测和降级处理,或者为不支持 Web Worker 的环境提供备用方案。
额外的内存消耗:
- 启动 Web Worker 意味着创建一个新的线程,会增加浏览器的内存开销。对于资源受限的设备(如低端移动设备),过多或不当使用的 Web Worker 可能导致内存溢出或其他性能问题。
通信成本:
- 主线程与 Web Worker 之间的通信需通过序列化和反序列化数据,这会带来一定的性能开销。如果更新过程中频繁进行大量数据交换,可能会抵消部分多线程带来的优势。
限制访问某些对象与 API:
- Web Worker 环境中无法直接访问
window、document等与DOM相关的全局对象,也无法直接操作 DOM。对于依赖这些功能的更新逻辑,需要通过消息传递将相关操作委托给主线程执行。
- Web Worker 环境中无法直接访问
调试复杂性:
- 由于 Web Worker 运行在独立线程中,调试起来可能比主线程代码更为复杂。开发者需要使用专门的工具或技巧来监控和调试 Worker 中的代码。
总结来说,使用 Web Worker 实现网站更新有利于提升用户体验、优化性能和代码结构,但同时也需要注意其可能带来的兼容性问题、额外资源消耗、通信成本、API 访问限制及调试复杂性。在实际应用中,应根据具体场景权衡利弊,合理利用 Web Worker 以实现高效、流畅的网站更新流程。
视频效果预览
 wechat
wechat- alipay






